For this chapter, we will use Aridity index (AI), which is a popular metric for climate classification based on the relative availability of Mean Annual Precipitation (P) compared to the Mean Annual Reference Evapotranspiration (ET0) of a location. Aridity Index is defined as: \(AI= P / ET_0\). Here, ET0 is the maximum potential amount of moisture a hydrologic system can transfer to atmosphere through evaporation and transpiration. The value of \(P / ET_0\) progressively increases from arid to humid regions. Since P and ET0 can never be negative, AI is always >0.
Global Climate Classification Map Based on Aridity Index
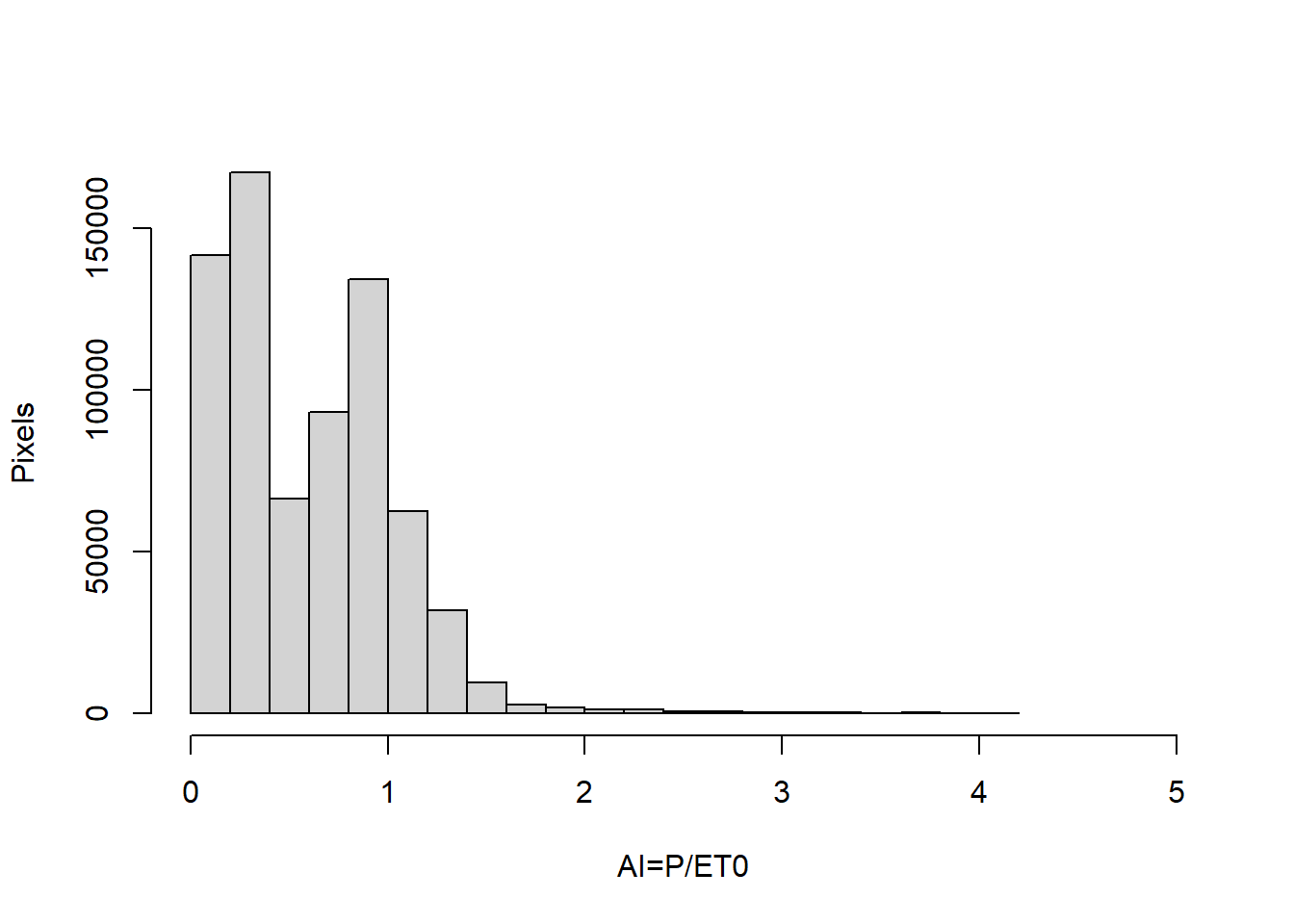
For the purpose of this demonstration, we will use CONUS-wide raster of aridity index estimates (i.e. P/ET0) provided by (Zomer, Xu, and Trabucco 2022), at ~0.8X0.8 KM spatial resolution. Let us first start by downloading the sample data files (refer to previous chapters for the code). We will then import the raster and plot a histogram of the raster to understand the probability distribution of the AI values. Do we agree that most pixels in the raster range within 0-4?
library(terra)AI=terra::rast("./SampleData-master/raster_files/P_over_ET0.tif") # Let us plot a histogram of the rasterhist(AI, breaks=20, xlim=c(0,5), xlab="AI=P/ET0", ylab="Pixels", main="")
# We observe most values in the raster are <4. So, we set the range of the plot accordinglyterra::plot(AI, main="AI=P/ET0", range=c(0,4))
5.2 Raster Resampling
We have so far worked with global surface soil moisture raster (from SMAP) and we are familiar with its spatial distribution across the globe. Now, let us consider this question:
How does the climate impact the spatial distribution of soil moisture?
One approach of answering the question can be to compare pixel values of SMAP soil moisture with corresponding values of AI to establish the bivariate AI–SM relationship. So, we must first change the resolution of AI raster to match that of the SMAP soil moisture. For this, we will use raster resampling.
Raster resampling simply refers to making changes to the pixel resolution of the raster. The term “resampling” implies that the pixel values are “sampled” and reassigned to the pixels at the new resolution. This operations often involves an interpolation method (nearest neighbor, bilinear, spline, min, max, mode, average etc). We will try three important functions for changing the resolution of a SpatRaster:
terra::resample - resample to match the resolution of another raster
terra::aggregate - resample from fine to coarse resolution
terra::disagg - resample from coarse to fine resolution
Raster resampling can be a critical step during multivariate analysis, where raster pixels must overlap to ensure the datasets from each raster corresponds to the same spatial domain. The following schematic helps illustrate the use of these functions:
5.2.1 Why Resample?
To explore the AI–SM relationship, first, we will resample the pixels in the AI raster to match the spatial resolution of sm pixels using the terra::resample function with bilinear interpolation method. This method estimates new cell values as a weighted-average values of the adjoining pixels. The weights are calculated according to the distance of the target pixel from the adjoining cells. In addition to the bilinear approach, terra::resample has several other interpolation methods available as options such as near (for nearest neighbor interpolation), cubic, sum, min, max, average , rms (root-mean square) etc. For more information on resampling methods within the context of remote sensing, please refer to (Schowengerdt 2007).
Once AI raster is resamapled to match sm, we would then be able to generate scatter plots between the two rasters, and evaluate the relationship between aridity index (climate) and soil moisture. We see that the soil moisture increases as AI increases before reaching an asymptotic value as AI>1 (humid climate, indicated by red vertical line in the plot). This relationship follows the famous Budyko formulation of energy and water limits on terrestrial water balance (Chen and Sivapalan 2020). For illustration, we use a simple formulation of Budyko curve to represent the non-linear interrelationship between AI and soil moisture given as:
\[
SM=AI/(1+AI)^{1.5}
\]
sm=terra::rast("./SampleData-master/raster_files/SMAP_SM.tif") AIResamp=terra::resample(AI, # Raster to be resmapled sm, # Target resolution rastermethod='bilinear') # bilinear interpolation method# Check the resolution of the aridity raster after resamplingres(AIResamp)
Food for thought: Can we do this analysis had we used AI raster instead of AIResamp? What will be the output is we replace AIResamp with AI in the code above.
5.2.2 Aggregation and Disaggregation
Now that we have seen the application of terra::resample function, let us now try terra::aggregate and terra::disagg when we know the factor of (dis)aggregation to be used in each direction. Several functions are available for raster aggregation including mean, max, min, median, sum, modal, sd. Disaggregation can use either near or bilinear methods.
library(terra)# Import AI rasterAI=terra::rast("./SampleData-master/raster_files/P_over_ET0.tif") # Remove the negative fill value from AI rasterAI[AI<0]=NA# Original resolution of raster for referenceres(AI)
[1] 0.008333333 0.008333333
#~~ Aggregate raster to coarser resolutionAIcoarse = terra::aggregate(AI, # Original AI rasterfact =100, # Reduce the spatial dimension by a factor of 100fun = mean, # Function used to aggregate values. We use within-pixel meanna.rm=TRUE) # Ignore NA valuesres(AIcoarse) # Resolution changed from 0.8KMX0.8KM to (0.8X100KM)x(0.8X100KM)
[1] 0.8333333 0.8333333
plot(AIcoarse, main="Aggregated AI raster")
#~~ Disaggregate AI to finer resolutionAIfine = terra::disagg(AI, fact=2, # Reduce the spatial dimension by a factor of 2method='bilinear') # Interpolation method "bilinear" or "near" res(AIfine) # Resolution changed from 0.8KM X 0.8KM to (0.8/2KM)x(0.8/2KM)
[1] 0.004166667 0.004166667
plot(AIfine, main="Disggregated AI raster")
5.3 Cropping and Masking
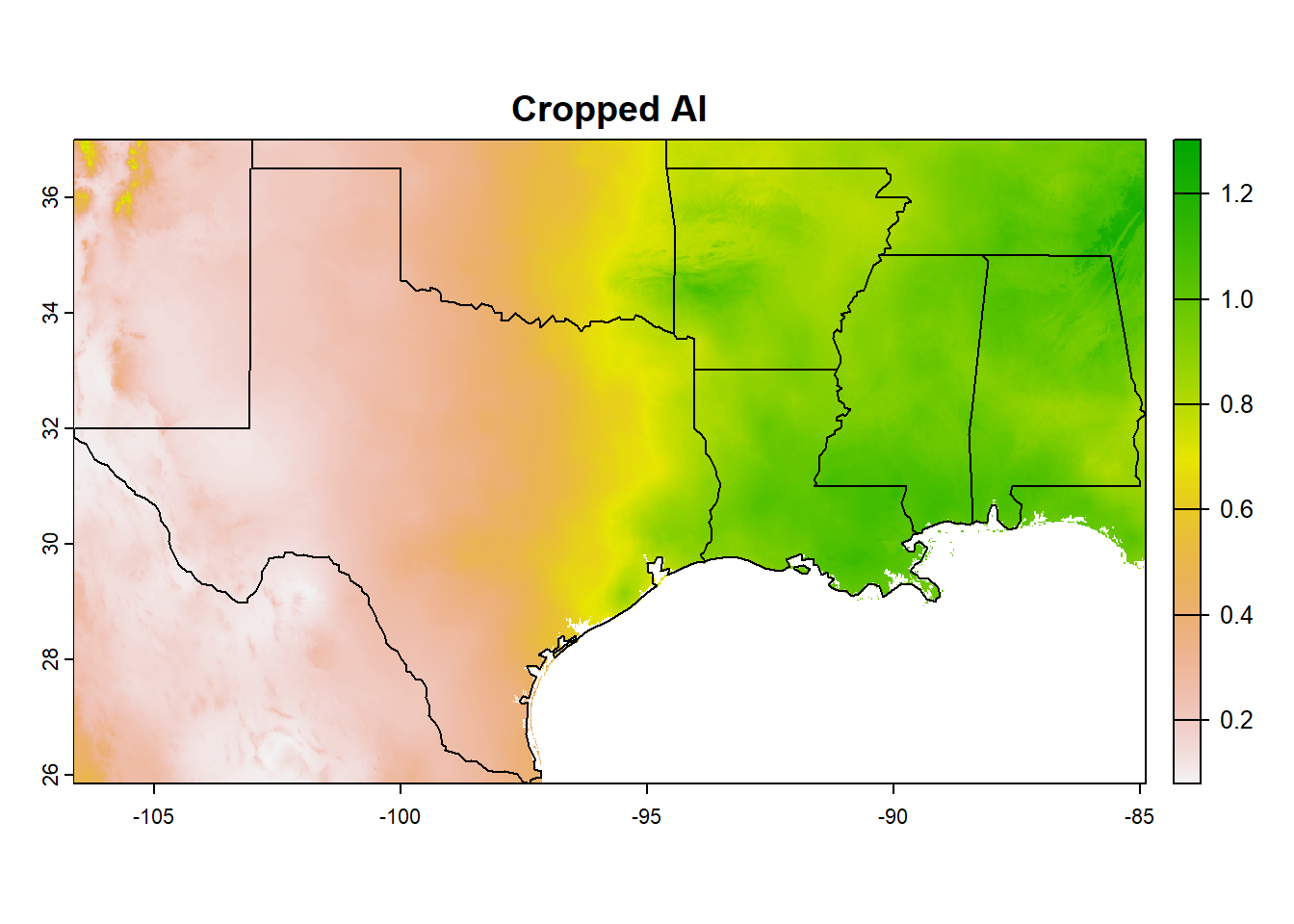
Cropping and masking operations are used to reduct the spatial extent of a raster/vector data. We will use US states shapefile from spData::us_states to select the polygons for Louisiana and adjoining states. The resource spData::us_states provides features for the Contiguous U.S. as simple feature, i.e., sf collection. We note that the state names in the us_states multipolygon are given in the field NAME, which we will use to subset the multipolygon to the specific states we are interested in. We will take “Louisiana”, “Texas”, “Mississippi”,“Alabama”, “Oklahoma”, “Arkansas” as examples.
library(spData)library(sf)AI=terra::rast("./SampleData-master/raster_files/P_over_ET0.tif") # Lets view the datahead(spData::us_states)
Simple feature collection with 6 features and 6 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -114.8136 ymin: 24.55868 xmax: -71.78699 ymax: 42.04964
Geodetic CRS: NAD83
GEOID NAME REGION AREA total_pop_10 total_pop_15
1 01 Alabama South 133709.27 [km^2] 4712651 4830620
2 04 Arizona West 295281.25 [km^2] 6246816 6641928
3 08 Colorado West 269573.06 [km^2] 4887061 5278906
4 09 Connecticut Norteast 12976.59 [km^2] 3545837 3593222
5 12 Florida South 151052.01 [km^2] 18511620 19645772
6 13 Georgia South 152725.21 [km^2] 9468815 10006693
geometry
1 MULTIPOLYGON (((-88.20006 3...
2 MULTIPOLYGON (((-114.7196 3...
3 MULTIPOLYGON (((-109.0501 4...
4 MULTIPOLYGON (((-73.48731 4...
5 MULTIPOLYGON (((-81.81169 2...
6 MULTIPOLYGON (((-85.60516 3...
# From this we will subset the sf object for the selected states. We select forst column as we are only interested in a single attributeUS_shp=spData::us_states# Subset selected states from the shapefilesouth_sf=US_shp[US_shp$NAME %in%c("Louisiana", "Texas", "Mississippi","Alabama", "Oklahoma", "Arkansas"),]# Convert the sf object to SpatRastersouth_vect=vect(south_sf)plot(south_vect)
# Mask AIfine raster to match south_vect spatial domain AI_south_msk=mask(AI_south, south_vect) # Try: inverse=TRUE argument for funplot(AI_south_msk, main="Masked AI")plot(south_vect, add=T)
Computing Counsel
For large rasters, it is computationally efficient to crop and/or mask rasters to the region of interest before the analysis.
crop first, and mask later, as masking is computationally expensive than cropping.
5.4 Raster RATification
In the AI plot above, we see the expected climate pattern for the terrestrial landmass. The eastern U.S. receives abundant precipitation, and have high aridity index values. In contrast, Southwestern US have hot and dry climate, and show low values of the aridity index. However, in common use, we are more familiar with the use of generalized climate categories, and not a numerical index. For example, its easier to understand, compare and contrast the difference between the climate of Arizona and Louisiana in terms of “arid” versus “humid”, than the respective AI values.
Such terms come from the United Nations Environment Program (UNEP, (Nash 1999)), that divides global climate in five discrete classes based on the aridity index as below:
Table 1: Aridity Index based climate classes given by UNEP
An attribute table can be added to a raster which serves as a look-up reference for the discrete classification of the continuous variable in the raster. This process of adding a Raster Attribute Table to a raster is called raster RAT-ification.
As an example, we will follow class breaks and names given in Table 1 to add a climate attribute to the AI raster. We will cut the pixel values of the AI raster into discrete classes and add the attribute table back to the original AI raster.
# Import AI raster and remove negative fill valueAI=terra::rast("./SampleData-master/raster_files/P_over_ET0.tif") # Breaks for each climate class from Table 1class_brk=c(0, 0.03, 0.2, 0.5, 0.65, 10) # Labels for each climate class from Table 1class_names=c("Hyper arid", "Arid", "Semi arid", "Sub humid", "Humid") # Divide the cell values in the AI raster into distinct levelsattributes=base::cut(values(AI), # Notice we apply cut on raster "values" breaks = class_brk,labels =class_names )# Add attributes to the SpatRaster as climate classAI$climate = attributesplot(AI$climate, plg =list(loc ="bottomleft"))
5.5 Zonal Statistics
Zonal statistics refers to estimate statistical measures of the cell values of a raster within the zones of another dataset (raster/vector). In the subsequent examples, we will use the aridity index raster to create a polygon, demarcating the spatial boundaries of the discrete climate zones. We will then use these polygons to extract respective cell values and calculate zonal statistics for each climate.
5.5.1 Zonal Statistics with Polygons
5.5.1.1 Raster to Polygons
In the next example, we will convert the aridity raster into a polygon based on aridity classification using terra::as.polygons function. We will use previously RATified the aridity index raster to generate polygons for the climate zones.
# Convert classified raster to shapefilearid_poly=as.polygons(AI$climate) # Convert SpatRaster to a spatial polygon # Notice the dimension (geometries, attributes) and values of the polygon. # Do the values match the classes you created?print(arid_poly)